Machine Learning | Artificial Intelligence : SOME CONCEPTS (this page is under construction...)
|
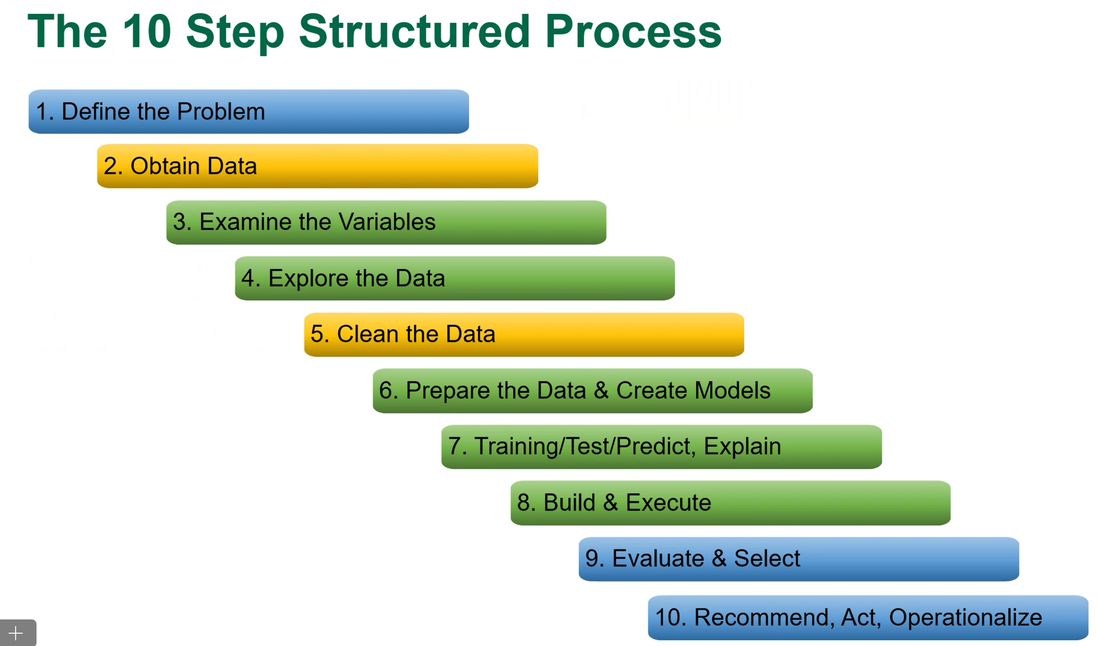


|
- Data Drift: Patterns change, shopping behaviors change, economies change, so there is a continuous need to update and upgrade the model, it's variables, need to be upgraded.
- Two types of Data: Primary Data - collected through regular business transactions
- Secondary Data:
- Binary Classifier: Test Data, Train Data, Validation Data
- Positive Prediction and It is a positive -> True Positive
- Negative Prediction and it is negative -> True Negative
- But model can make mistakes and predict a false positive and false negative.
- Accuracy= (True Positive + True Negatives)/Total Predictions
- Misclassification Rate = 100% - accuracy%
- What is the problem? The problem is all these algorithms give a probabilistic score and leave it upto us to decide whether to accept the risk or not. Example: 0.85 certainty that this transaction is a fraud.
- Sensitivity (healthcare) = True Positive Rate = Recall (memory based) -> how many positives compared to the actual positive were actually identified.
- Specificity = True Negative Rate = TN/Negatives
- There is always a trade off between Sensitivity and Specificity. The more sensitive you get the less specific results may get.
- F1Score=2/[(1/Recall)+(1/Precision)]
- So, a good model has high accuracy, high specificity, and high sensitivity.
- Important Questions to ask: what is the cost of false negative for the scenario or the cost of false positive.
- Dependent variable and independent variable.
- Expected value calculations and cost benefit analysis are critical to making a real business decision.
- MARKET BASKET ANALYSIS
- Bundling items together and suggesting the buyers on what items they should/can buy is the result of market basket analysis.
- Support and Confidence:
- Support for an Item A is 75% when it's in 3 out of 4 shopping carts.
- Confidence in a combination of items example A&C together:Support for (A&C)/Suport(A) or Support for (A&C)/Suport(C) meaning, every time a customer picks A, 66% of times he picks C and every time customer picks C, he always picks A =100% (based on given data) respectively.
- Rules:
- 1)
- 1) Associatie Rule:
-
| intelligent_cloud_computing.pdf |